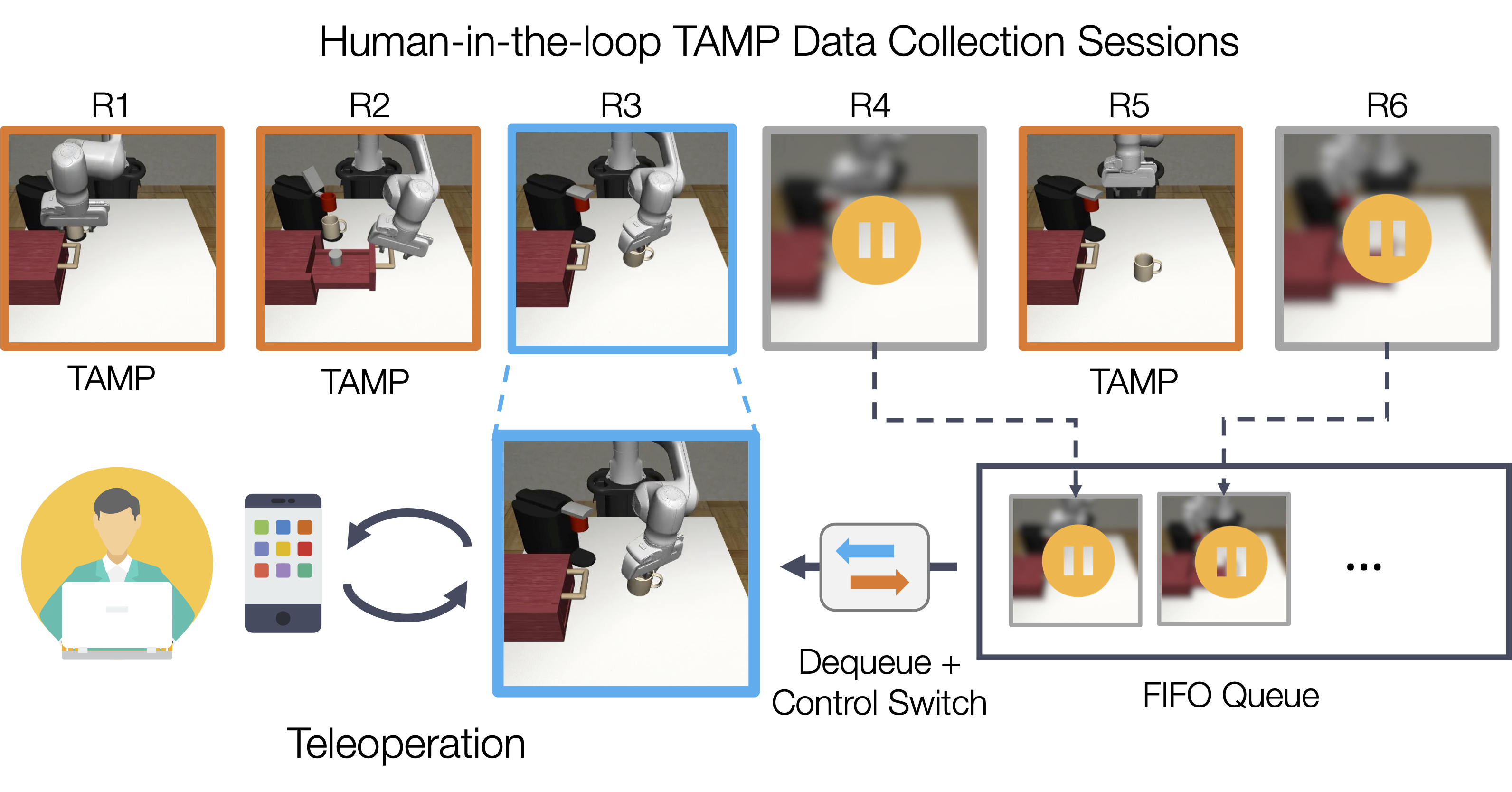
During data collection, the TAMP system defers task portions it does not know how to complete to a human operator. This greatly reduces the data collection burden on the human operator, who does not need to demonstrate the full task.
During deployment, TAMP defers task portions to an autonomous robot trained via imitation learning on the collected data. This enables TAMP to work for contact-rich manipulation without accurate models.
Long-horizon tasks can be difficult for standard imitation learning approaches. By contrast, the HITL-TAMP framework easily scales to long-horizon tasks such as this coffee preparation task, which consists of 8 stages (4 TAMP and 4 policy segments).
HITL-TAMP trains proficient real-world agents on challenging contact-rich and long-horizon manipulation
HITL-TAMP policy can solve the challenging Tool Hang task.
HITL-TAMP policy is robust to different initializations.
Stack Three
Coffee Broad
Coffee
HITL-TAMP greatly accelerates data collection and often trains near-perfect agents from this data
Queueing System
Since humans only need to demonstrate small pieces of each task, they can participate in several data collection sessions at once. Human operators interact asynchronously with a fleet of several robots using our queueing system, which schedules tasks to ensure humans are always kept busy, enabling large-scale data collection.
Dataset Visualizations
We collected 2.1K+ demos using the system across these tasks. This took a single operator a few hours, as opposed to operator teams and days needed in prior work. Similarly, in our user study, given a fixed time budget, users collected much more data with HITL-TAMP (over 3x more) compared to conventional teleoperation.
Square
Square Broad
Three Piece Assembly
Three Piece Assembly Broad
Coffee
Coffee Broad
Coffee Preparation
Tool Hang
Tool Hang Broad
Trained Policies
Each policy below was trained on 200 demos from HITL-TAMP. Several policies are near-perfect.
Square (100%)
Square Broad (100%)
Three Piece Assembly (100%)
Three Piece Assembly Broad (85%)
Coffee (100%)
Coffee Broad (99%)
Coffee Preparation (96%)
Tool Hang (81%)
Tool Hang Broad (49%)
HITL-TAMP can train performant agents from just 10 minutes of data provided by operators with little to no teleoperation experience
The policies below were trained on just 10 minutes of operator data from an operator with little to no experience with teleoperation. We compare policies trained on 10 minutes of HITL-TAMP data and 10 minutes of conventional teleoperation data.
Coffee
HITL-TAMP (100%)
Conventional (28%)
Square Broad
HITL-TAMP (84%)
Conventional (0%)
Three Piece Assembly Broad
HITL-TAMP (22%)
Conventional (0%)
Task Reset Distributions
Below, we show the reset distributions for each task.
Square
Square Broad
Three Piece Assembly
Three Piece Assembly Broad
Coffee
Coffee Broad
Coffee Preparation
Tool Hang
Tool Hang Broad
Stack Three Real
Coffee Real
Coffee Broad Real
Tool Hang Real
Real World Data Collection
The videos below are from the HITL-TAMP datasets that we used to train our real world agents. The video resolutions match the image resolutions used for policy training.
Stack Three Real
Coffee Real
Coffee Broad Real
Tool Hang Real
Full Supplemental Video
BibTeX
@inproceedings{mandlekar2023hitltamp,
title={Human-In-The-Loop Task and Motion Planning for Imitation Learning},
author={Mandlekar, Ajay and Garrett, Caelan and Xu, Danfei and Fox, Dieter},
booktitle={7th Annual Conference on Robot Learning},
year={2023}
}Acknowledgements
This work was made possible due to the help and support of Sandeep Desai (robot hardware), Ravinder Singh (IT), Alperen Degirmenci (compute cluster), Yashraj Narang (valuable discussions), Anima Anandkumar (access to robot hardware), Yifeng Zhu (robot control framework), and Shuo Cheng (drawer design used in Coffee Preparation task). We also thank all of the participants of our user study for contributing their valuable time and feedback on their experience.